---
title: llmstxt for blogs
subtitle: Extending `llms.txt` for Blogs – Give Your LLM an All-Access Pass
tags: [llmtxt, blog]
created_at: 2025-06-02
---
The `llms.txt` proposal ([llmstxt.org](https://llmstxt.org/index.md)) presents a fascinating idea for providing LLM-friendly content, primarily showcased with documentation for projects like FastHTML. It offers a structured avenue for models to access concise, expert-level information.
But what if we explored taking this concept a step further? Could this approach, initially designed for docs, be adapted and extended for the rich, diverse content found on blogs?
## Exploring the Idea: `llms.txt` for Bloggers
Imagine a scenario where your blog isn't just human-readable, but also intentionally LLM-optimized. By potentially extending the `llms.txt` concept, we could explore creating a manifest that points LLMs to the full text of our posts, curated bookmarks, and other relevant metadata.
I've started experimenting with this concept on my own blog. Here's what my site currently generates:
* A main [llms.txt](https://eug.github.io/llms.txt) with blog metadata, about section, and pointers.
* [llms-posts-full.txt](https://eug.github.io/llms-posts-full.txt): All blog posts in raw Markdown, concatenated.
* [llms-bookmarks-full.txt](https://eug.github.io/llms-bookmarks-full.txt): All shared bookmarks in Markdown.
This early experiment aims to provide a richer, structured dataset for LLMs to potentially work with, right from the source.
## A Key Consideration: Licensing and Data Use
Before diving into potential use cases, it feels crucial to consider the digital handshake we might be making when publishing an `llms.txt` file for our blogs. If we provide this structured, LLM-friendly access to our content, are we, in essence, signaling an intent? It seems plausible that this could be interpreted as granting permission for the data to be used in ways that LLMs excel at – which might include, but isn't necessarily limited to:
* **Training and Fine-tuning:** Could your content become part of the vast datasets used to train future models or fine-tune existing ones on specific styles or topics (like your blog's niche)?
* **Remixing and Derivative Works:** Might LLMs use your content as a basis for generating new text, summaries, or even entirely new creative works derived from or inspired by your posts?
* **Indexing and Analysis:** Beyond simple search, could your content be deeply indexed, analyzed for patterns, and cross-referenced in new ways?
This isn't about suggesting a renounce of copyright wholesale, but rather acknowledging that the act of making blog content explicitly available and optimized for machine consumption could carry an implicit consent for these kinds of transformative uses. Is it a *quid pro quo*: we give models better data, and in return, those models can do more interesting things with it, potentially amplifying our blog's reach and impact in new ways? If one isn't comfortable with their content being used this way, then perhaps providing an `llms.txt` wouldn't be the right step.
For those of us who see this as an exciting frontier to explore, it could be a way to actively participate in how AI understands and interacts with the wealth of knowledge and creativity shared on personal blogs.
## From SEO to AEO with `llms.txt`?
The digital landscape appears to be in a period of significant flux. For years, Search Engine Optimization (SEO) was a central focus, emphasizing keywords and rankings to gain visibility on Search Engine Results Pages (SERPs). However, as highlighted by emerging concepts like Answer Engine Optimization (AEO) (see [SurferSEO's article on AEO](https://surferseo.com/blog/answer-engine-optimization/)), the game seems to be evolving. Users, increasingly interacting with AI assistants and sophisticated search tools, now often expect direct answers and conversational results, not just a list of links.
Answer Engines, powered by advanced AI and Natural Language Processing, aim to understand user *intent* and provide precise, concise answers. This is where the idea of `llms.txt` for blogs could become particularly relevant.
* **Direct Value Delivery:** AEO emphasizes providing answers upfront. An `llms.txt` file, by its very structure, offers a way to give LLMs a direct, no-nonsense summary and pathway to a blog's core content. It's like handing the answer engine the keys to your knowledge base.
* **Structured for Understanding:** AEO thrives on well-structured content. Schema markup and clear formatting help answer engines interpret and display information effectively. The proposed `llms.txt` format, with its defined sections and Markdown structure, provides a similar level of clarity specifically tailored for LLM consumption.
* **Aligning with Modern Search Behaviors:** Users are asking questions in natural language, often through voice search or AI chatbots, for which traditional SEO isn't always optimized. An `llms.txt` can help bridge this gap by making a blog's content more readily digestible and understandable for the AI systems that power these new interfaces.
* **Building Authority in an Age of Answers:** AEO is about establishing content as an authoritative source that provides clear, direct answers. By curating what an LLM sees first through `llms.txt`, bloggers can better position their expertise and ensure their core messages are more easily found and understood by these new information gatekeepers.
In essence, exploring the adoption of `llms.txt` for blogs might not just be about feeding data to a model; it could be a strategic move to align with the principles of AEO. It's potentially about future-proofing content and ensuring it remains visible and valuable as search paradigms evolve from keyword matching to intent fulfillment and direct answer provisioning.
## Potential Use Cases for an LLM-Optimized Blog:
What could an LLM-optimized blog unlock? Here are a few possibilities:
1. **Smarter Q&A:**
* Could users (or the LLM itself) ask complex questions spanning multiple posts? E.g., "What are the common themes in posts tagged 'AI' from the last year?"
* Might we get answers based *only* on the blog's content, potentially reducing hallucinations?
2. **Content Generation & Augmentation Ideas:**
* Could it help draft a new blog post in the style of a 'Python Tips' series, focusing on asynchronous programming?
* Might it suggest alternative titles for a draft post?
* Could it generate a summary of a 'Project X Retrospective' series?
3. **Enhanced Search & Discovery Possibilities:**
* Could one perform semantic searches across all articles and even curated bookmarks? E.g., "Find articles discussing 'serverless architectures' and any related bookmarks saved."
* Could an LLM assist in auto-tagging posts or suggesting related articles with much higher accuracy?
4. **Personalized Experiences (Further Down the Line?):**
* Imagine an LLM-powered agent that has processed an entire blog. Could it offer personalized summaries or learning paths based on a user's query and the blog's content?
5. **Data Portability & Analysis Opportunities:**
* Could one more easily feed an entire body of work into different LLM tools or local models for analysis, without complex scraping?
Ultimately, these are just a few initial thoughts. The core idea is that by making our blog content more accessible and understandable to LLMs, we could unlock entirely new ways for readers (and ourselves) to interact with, synthesize, and draw connections across our accumulated knowledge. Imagine an experience where insights from multiple related posts are seamlessly integrated together in response to a query, creating a much richer and more dynamic form of content consumption than simply reading individual articles in isolation. The potential to transform blog reading into a more interactive, interconnected journey seems quite exciting.
## A Practical Dive: Unlocking Bookmark Insights with NotebookLM
I've been experimenting with ways to make my bookmarks more accessible to the general public, moving away from private silos – a journey I detailed in my post "[My bookmarks are public now](my-bookmarks-are-public-now.html)". Part of this exploration involves not just making them public, but also easier to query and gain insights from, even in their raw, unstructured form. We all have bookmarks, right? Traditionally, making them useful meant meticulous tagging, and revisiting them. But what if we could just... not, or at least, less so?
I've been playing around with feeding my blog's [llms-bookmarks-full.txt](https://eug.github.io/llms-bookmarks-full.txt) into tools like Google's NotebookLM.
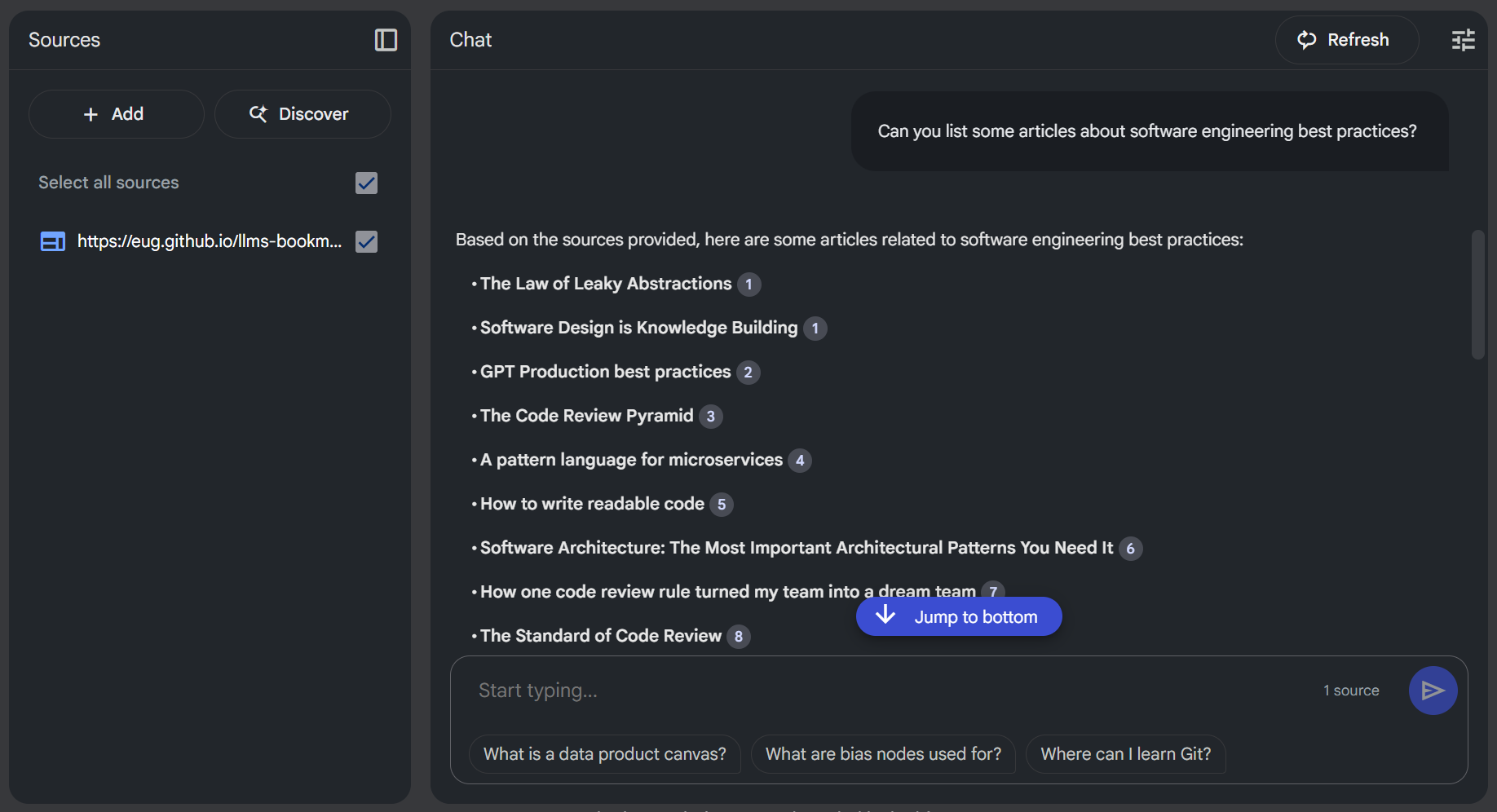
The experience is quite revealing. For example, one could ask a general question like *"Can you list some articles about software engineering best practices?"* and the system can pull relevant links directly from that raw, unstructured list of bookmarks. Suddenly, there's potential to get insights and answers from saved links *without any upfront organization* – a task that used to consume considerable time. It's like having a research assistant that's already processed everything bookmarked. This could dramatically lower the barrier to actually *using* our digital breadcrumbs.
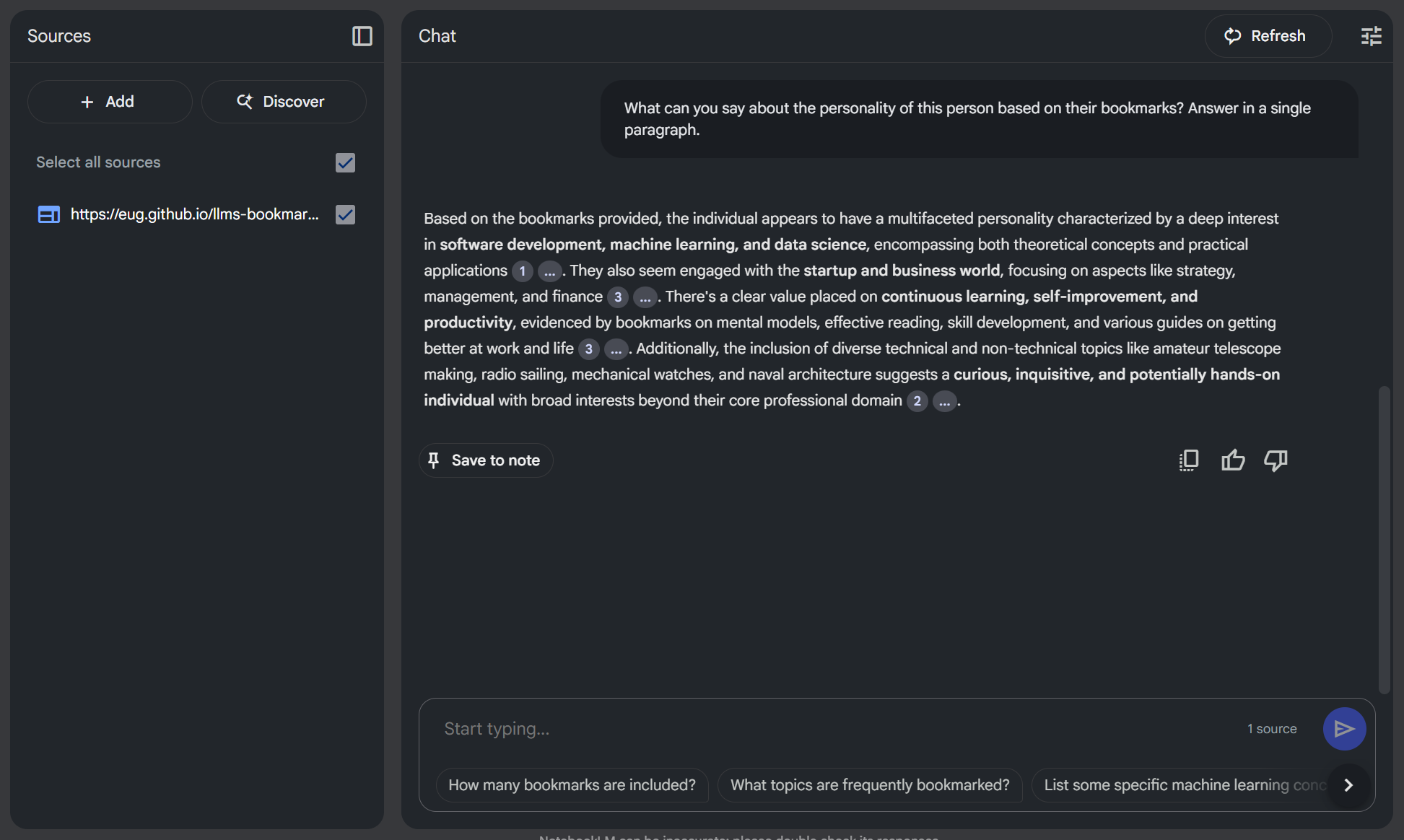
 Going a step further, as shown in the second image, one might even explore more abstract queries. For instance, posing a question like, *"What can you say about the personality of this person based on their bookmarks?"* yielded a response that was, it's worth noting, quite accurate given the nature of the saved links. This hints at the potential for LLMs to draw higher-level inferences from curated data, moving beyond simple information retrieval into areas that feel more akin to understanding an individual's interests and perhaps even their thought patterns, all derived from their digital trail.
Going a step further, as shown in the second image, one might even explore more abstract queries. For instance, posing a question like, *"What can you say about the personality of this person based on their bookmarks?"* yielded a response that was, it's worth noting, quite accurate given the nature of the saved links. This hints at the potential for LLMs to draw higher-level inferences from curated data, moving beyond simple information retrieval into areas that feel more akin to understanding an individual's interests and perhaps even their thought patterns, all derived from their digital trail.
 If you're curious to try it yourself, you can chat directly with my bookmarks by visiting [Google NotebookLM](https://notebooklm.google.com/notebook/65911a6f-ce1b-4604-bb7d-178aa88f67ea?original_referer=https%3A%2F%2Fwww.google.com%23&pli=1).
## Wrap up
So, what if we started thinking more intentionally about how our blogs feed into these rapidly evolving language models? The experiment with NotebookLM, simply by pointing it at a raw list of bookmarks, offers a small taste of the potential. Imagine the richer interactions and deeper insights we could unlock if we consciously provided LLMs with access to our full posts and curated links in a more structured, yet still easily manageable way.
Whether or not foundational model companies decide to prioritize direct ingestion of such `llms.txt` files (or similar conventions) remains to be seen. However, the value for individual creators and their audiences in making content more AI-accessible might be a compelling enough reason to explore these paths. It empowers us to leverage a growing ecosystem of AI tools with our own curated knowledge bases, on our own terms.
This isn't about a rigid specification, but rather an open invitation to explore. How might we, content creators, make our digital footprints more readily useful for these new forms of AI-driven discovery and synthesis? What other simple experiments could we run? What are your thoughts on extending concepts like `llms.txt` to the world of blogging, or other creative approaches to bridge our content with AI?
___
---
title: My bookmarks are public now
subtitle: Rethinking bookmarks for the next decade
tags: [vibe-code, ssg, python, bookmark]
created_at: 2025-06-01
---
So, [Pocket's shutting down](https://getpocket.com/farewell). Cue the minor existential crisis for a 10-year power user like myself. Over a thousand articles saved – a digital trail of my internet rabbit holes and "aha!" moments. The announcement hit, and it wasn't just about losing a service; it was about realizing how much of that curated knowledge was locked away, just for me. And the big question: migrate to another silo, or... something else?
I chose "something else."
The thought of another decade of private bookmarking, another walled garden of links, just didn't sit right. Why store up all this good stuff? Why not make it a public, evolving resource? And even better, why not let others chip in?
That's the new plan: **Public, collaborative, and interactive bookmarks.**
Here are the details on how I'm pulling this off:
**Public**
First, liberation. I grabbed my Pocket data (shoutout to them for a clean CSV export). Then came the data-janitor phase (it took me several hours to finish it): I did some cleaning, replaced old links with updated ones, pruned the dead links, and removed articles that were well past their sell-by date. This newly-curated treasure trove of links is now living on a plain HTML [bookmarks.html](https://eug.github.io/bookmarks.html) page on my site. Simple and effective.
**Collaborative**
Now, for the collaborative bit – this is where it gets fun (and very GitHub-y). I've added an "Add Bookmark" button. Clicking it doesn't pop up a sleek modal or hit a fancy API. Nope. It throws you straight into the GitHub editor for that [templates/bookmarks.html](https://github.com/eug/eug.github.io/edit/main/templates/bookmarks.html#L14) file.
The idea is beautifully simple:
1. I/You find a cool link.
2. I/You click "Add Bookmark."
3. I/You paste the URL and title into the HTML (minimal formatting needed, I'll tidy it up).
4. I/You submit a Pull Request.
5. I review, merge, and boom – my/your contribution is live for everyone.
Is it as slick as Pocket's one-click save? Nah. The beauty is in its transparency and the "good enough" approach. I can quickly paste a link myself without fuss, knowing I'll circle back to format it properly later during a review.
**Interactive**
But just *having* them public is one thing. How about making them truly *interactive*? That's where things get even cooler. I've started playing around with feeding this whole heap of bookmarks into Google's NotebookLM. What's the upshot? Well, it means anyone can now 'chat' with my bookmarks – ask questions, dig for specific topics, or even spot broader themes, all without manually combing through hundreds of links. You can jump in and query my bookmark collection directly here: [Google NotebookLM](https://notebooklm.google.com/notebook/65911a6f-ce1b-4604-bb7d-178aa88f67ea?original_referer=https%3A%2F%2Fwww.google.com%23&pli=1).
---
This isn't just about replacing a tool; it's an experiment in open knowledge sharing. Will anyone else contribute or interact? Maybe, maybe not. But the door's open. And either way, my digital breadcrumbs are now out in the open, hopefully leading others to some of the awesome corners of the web I've stumbled upon.
Let's see what the next decade of *open* bookmarking brings.
___
---
title: Vibe-code your own SSG
subtitle: Stop wrestling with frameworks. Vibe code your own lean static site generator.
tags: [vibe-code, ssg, python, minimalist, DIY]
created_at: 2025-06-01
---
So you want a simple blog. Just a place to jot down your experiments, share some thoughts. Static HTML is the obvious, robust choice. But writing raw HTML like it's 1999? Nah. You want Markdown, maybe a sprinkle of templating, a way to manage posts without pulling your hair out.
The usual suspects – [Jekyll](https://jekyllrb.com/), [Astro](https://astro.build/), [Hugo](https://gohugo.io/) – they're powerful, sure. But they can also feel like bringing a bazooka to a knife fight. Dependencies, complex configurations, a whole ecosystem to learn. What if you just want to get your words out there, with minimal fuss?
I hit this point recently and decided to "vibe-code" my own Static Site Generator (SSG). Turns out, it's surprisingly straightforward and a great way to understand what these tools actually *do*. Forget the bloat; let's vibe-code something lean.
## Here's the bare-bones recipe
**0. Programming Language: Your Choice**
Honestly, pick your poison. Python, Node.js, Ruby, even a shell script if you're feeling particularly masochistic. The core logic is simple enough for any modern language. I went with Python because its standard library is packed with goodies for file manipulation, and excellent libraries for Markdown and templating (like `Markdown` and `Jinja2`) are a `pip install` away. The key is picking something you're comfortable with and that won't get in your way.
**1. The Generation Script: Your SSG's Heart**
This is where the magic happens. At its core, your script will:
* **Scan for content:** Find all your Markdown files (your blog posts).
* **Parse metadata:** Extract frontmatter (title, date, tags, etc.) from each post. YAML or JSON are common choices here. Most Markdown libraries can handle this.
* **Convert Markdown to HTML:** Transform your post content into web-friendly HTML.
* **Apply templates:** Inject the generated HTML and metadata into your base HTML templates (e.g., one for a single post, one for the homepage).
* **Write output:** Save the final HTML files to a designated output directory (often `dist` or `public`).
Keep it simple. You don't need a complex plugin architecture for version 0.1. Focus on the core transformation pipeline.
**2. Templates Folder: The Skeleton of Your Site**
These are your HTML blueprints. You'll likely want at least:
* `base.html`: The main site structure (header, footer, navigation). Other templates will extend this.
* `post.html`: How a single blog post is displayed.
* `index.html` (or `home.html`): Your homepage, probably listing recent posts.
Templating engines like Jinja2 (Python), Handlebars (JavaScript), or Liquid (Ruby, and what Jekyll uses) are your friends here. They let you use variables, loops, and includes to keep your HTML DRY (Don't Repeat Yourself).
Example `post.html` (Jinja2-ish):
```html
{% extends "base.html" %}
{% block title %}{{ post.title }}{% endblock %}
{% block content %}
If you're curious to try it yourself, you can chat directly with my bookmarks by visiting [Google NotebookLM](https://notebooklm.google.com/notebook/65911a6f-ce1b-4604-bb7d-178aa88f67ea?original_referer=https%3A%2F%2Fwww.google.com%23&pli=1).
## Wrap up
So, what if we started thinking more intentionally about how our blogs feed into these rapidly evolving language models? The experiment with NotebookLM, simply by pointing it at a raw list of bookmarks, offers a small taste of the potential. Imagine the richer interactions and deeper insights we could unlock if we consciously provided LLMs with access to our full posts and curated links in a more structured, yet still easily manageable way.
Whether or not foundational model companies decide to prioritize direct ingestion of such `llms.txt` files (or similar conventions) remains to be seen. However, the value for individual creators and their audiences in making content more AI-accessible might be a compelling enough reason to explore these paths. It empowers us to leverage a growing ecosystem of AI tools with our own curated knowledge bases, on our own terms.
This isn't about a rigid specification, but rather an open invitation to explore. How might we, content creators, make our digital footprints more readily useful for these new forms of AI-driven discovery and synthesis? What other simple experiments could we run? What are your thoughts on extending concepts like `llms.txt` to the world of blogging, or other creative approaches to bridge our content with AI?
___
---
title: My bookmarks are public now
subtitle: Rethinking bookmarks for the next decade
tags: [vibe-code, ssg, python, bookmark]
created_at: 2025-06-01
---
So, [Pocket's shutting down](https://getpocket.com/farewell). Cue the minor existential crisis for a 10-year power user like myself. Over a thousand articles saved – a digital trail of my internet rabbit holes and "aha!" moments. The announcement hit, and it wasn't just about losing a service; it was about realizing how much of that curated knowledge was locked away, just for me. And the big question: migrate to another silo, or... something else?
I chose "something else."
The thought of another decade of private bookmarking, another walled garden of links, just didn't sit right. Why store up all this good stuff? Why not make it a public, evolving resource? And even better, why not let others chip in?
That's the new plan: **Public, collaborative, and interactive bookmarks.**
Here are the details on how I'm pulling this off:
**Public**
First, liberation. I grabbed my Pocket data (shoutout to them for a clean CSV export). Then came the data-janitor phase (it took me several hours to finish it): I did some cleaning, replaced old links with updated ones, pruned the dead links, and removed articles that were well past their sell-by date. This newly-curated treasure trove of links is now living on a plain HTML [bookmarks.html](https://eug.github.io/bookmarks.html) page on my site. Simple and effective.
**Collaborative**
Now, for the collaborative bit – this is where it gets fun (and very GitHub-y). I've added an "Add Bookmark" button. Clicking it doesn't pop up a sleek modal or hit a fancy API. Nope. It throws you straight into the GitHub editor for that [templates/bookmarks.html](https://github.com/eug/eug.github.io/edit/main/templates/bookmarks.html#L14) file.
The idea is beautifully simple:
1. I/You find a cool link.
2. I/You click "Add Bookmark."
3. I/You paste the URL and title into the HTML (minimal formatting needed, I'll tidy it up).
4. I/You submit a Pull Request.
5. I review, merge, and boom – my/your contribution is live for everyone.
Is it as slick as Pocket's one-click save? Nah. The beauty is in its transparency and the "good enough" approach. I can quickly paste a link myself without fuss, knowing I'll circle back to format it properly later during a review.
**Interactive**
But just *having* them public is one thing. How about making them truly *interactive*? That's where things get even cooler. I've started playing around with feeding this whole heap of bookmarks into Google's NotebookLM. What's the upshot? Well, it means anyone can now 'chat' with my bookmarks – ask questions, dig for specific topics, or even spot broader themes, all without manually combing through hundreds of links. You can jump in and query my bookmark collection directly here: [Google NotebookLM](https://notebooklm.google.com/notebook/65911a6f-ce1b-4604-bb7d-178aa88f67ea?original_referer=https%3A%2F%2Fwww.google.com%23&pli=1).
---
This isn't just about replacing a tool; it's an experiment in open knowledge sharing. Will anyone else contribute or interact? Maybe, maybe not. But the door's open. And either way, my digital breadcrumbs are now out in the open, hopefully leading others to some of the awesome corners of the web I've stumbled upon.
Let's see what the next decade of *open* bookmarking brings.
___
---
title: Vibe-code your own SSG
subtitle: Stop wrestling with frameworks. Vibe code your own lean static site generator.
tags: [vibe-code, ssg, python, minimalist, DIY]
created_at: 2025-06-01
---
So you want a simple blog. Just a place to jot down your experiments, share some thoughts. Static HTML is the obvious, robust choice. But writing raw HTML like it's 1999? Nah. You want Markdown, maybe a sprinkle of templating, a way to manage posts without pulling your hair out.
The usual suspects – [Jekyll](https://jekyllrb.com/), [Astro](https://astro.build/), [Hugo](https://gohugo.io/) – they're powerful, sure. But they can also feel like bringing a bazooka to a knife fight. Dependencies, complex configurations, a whole ecosystem to learn. What if you just want to get your words out there, with minimal fuss?
I hit this point recently and decided to "vibe-code" my own Static Site Generator (SSG). Turns out, it's surprisingly straightforward and a great way to understand what these tools actually *do*. Forget the bloat; let's vibe-code something lean.
## Here's the bare-bones recipe
**0. Programming Language: Your Choice**
Honestly, pick your poison. Python, Node.js, Ruby, even a shell script if you're feeling particularly masochistic. The core logic is simple enough for any modern language. I went with Python because its standard library is packed with goodies for file manipulation, and excellent libraries for Markdown and templating (like `Markdown` and `Jinja2`) are a `pip install` away. The key is picking something you're comfortable with and that won't get in your way.
**1. The Generation Script: Your SSG's Heart**
This is where the magic happens. At its core, your script will:
* **Scan for content:** Find all your Markdown files (your blog posts).
* **Parse metadata:** Extract frontmatter (title, date, tags, etc.) from each post. YAML or JSON are common choices here. Most Markdown libraries can handle this.
* **Convert Markdown to HTML:** Transform your post content into web-friendly HTML.
* **Apply templates:** Inject the generated HTML and metadata into your base HTML templates (e.g., one for a single post, one for the homepage).
* **Write output:** Save the final HTML files to a designated output directory (often `dist` or `public`).
Keep it simple. You don't need a complex plugin architecture for version 0.1. Focus on the core transformation pipeline.
**2. Templates Folder: The Skeleton of Your Site**
These are your HTML blueprints. You'll likely want at least:
* `base.html`: The main site structure (header, footer, navigation). Other templates will extend this.
* `post.html`: How a single blog post is displayed.
* `index.html` (or `home.html`): Your homepage, probably listing recent posts.
Templating engines like Jinja2 (Python), Handlebars (JavaScript), or Liquid (Ruby, and what Jekyll uses) are your friends here. They let you use variables, loops, and includes to keep your HTML DRY (Don't Repeat Yourself).
Example `post.html` (Jinja2-ish):
```html
{% extends "base.html" %}
{% block title %}{{ post.title }}{% endblock %}
{% block content %}
{{ post.title }}
Published on: {{ post.date }}
{{ post.content_html | safe }}
{% endblock %}
```
**3. Assets Folder: The Style and Flair**
This is where your CSS, JavaScript (if any), images, and fonts reside. Your generation script will likely just copy these files directly into the output directory, maintaining their structure.
Start with a single `style.css`. You can always add more later. Resist the urge to install a massive CSS framework unless you *really* need it. A few well-crafted CSS rules can go a long way.
**4. Posts Folder: Your Content Hub**
A straightforward directory where each `.md` file is a blog post. A common convention is to name files like `YYYY-MM-DD-your-post-slug.md`. The frontmatter at the top of each file is key for your generation script.
Example post (`2025-06-01-my-first-post.md`):
```markdown
---
title: "My First Awesome Post"
date: 2025-06-01
tags: [introduction, exciting-stuff]
---
Hello world! This is my first post, generated by **my own** SSG.
It feels good.
```
**5. The "Extra Support" Goodies: Because Details Matter**
Once you have the basics, these aren't hard to add and make your site a better web citizen:
* `atom.xml` / `rss.xml`: An XML feed for aggregators. Your script can generate this by looping through your posts.
* `robots.txt`: Tells search engine crawlers what they can and cannot index.
* `sitemap.xml`: Helps search engines discover all the pages on your site.
* `CNAME` (if using a custom domain with services like GitHub Pages): A file containing just your custom domain name.
* `llms.txt` (optional, emerging): If you want to serve your site as context for LLMs.
## Bonus: Kickstart with an LLM
Feeling lazy or just want a quick starting point? Modern LLMs are surprisingly good at bootstrapping simple scripts. Try a prompt like this (tailor it to your preferences):
```text
Create a simple static site generator in Python. It should:
1. Read all `.md` files from a `posts` directory.
2. Parse YAML frontmatter (title, date) from each file.
3. Convert Markdown content to HTML.
4. Use Jinja2 templates from a `templates` directory: `base.html` and `post.html`.
5. `base.html` should define blocks for `title` and `content`. It should link to a `style.css` file.
6. `post.html` should extend `base.html` and display the post title and content.
7. Generate an `index.html` in a `dist` directory, listing titles and links to all posts, sorted by date (newest first).
8. Generate individual HTML files for each post in the `dist` directory (e.g., `dist/my-post-slug.html`).
9. Copy an `assets` directory (which should contain the `style.css`) to `dist/assets`.
10. The `style.css` should implement a clean, minimalist, responsive design with a dark theme. Use a sans-serif font for readability.
Provide the Python script, example minimal `base.html` and `post.html` templates, and a basic `style.css`.
```
>**Pro tip:** This works even better with AI IDEs like Cursor, Windsurf, or Cline rather than standalone LLMs. These tools can actually create the entire file structure for you automatically – the Python script, template files, CSS, even a sample blog post to test with. No copy-pasting required.
It may not give you a production-ready SSG, but it's a fantastic V0.0.1. You can then iterate, refactor, and add features as you see fit, truly making it your own.
*P.S. I used Cursor with Claude 4 Sonnet for the initial version, and it handled this prompt beautifully – complete with working templates and surprisingly decent CSS.*
## The Payoff? Control and Understanding.
Building your own SSG isn't just a technical exercise. It gives you complete control over your site, zero opaque dependencies, and a deeper understanding of how web content is structured and served. When something breaks, you know exactly where to look (or ask the LLM to do so). When you want a new feature, you're not fighting a framework; you're just adding a bit more code to *your* script.
So, before you reach for that heavy-duty SSG framework, ask yourself: could I just vibe-code this? You might be surprised how far a little bit of scripting can take you.